Abstract
The visual dubbing task aims to generate mouth movements synchronized with the driving audio, which has seen significant progress
in recent years. However, two critical deficiencies hinder their wide application: (1) Audio-only driving paradigms inadequately
capture speaker-specific lip habits, which fail to generate lip movements similar to the target avatar; (2) Conventional blind-inpainting
approaches frequently produce visual artifacts when handling obstructions (e.g., microphones, hands), limiting practical deployment.
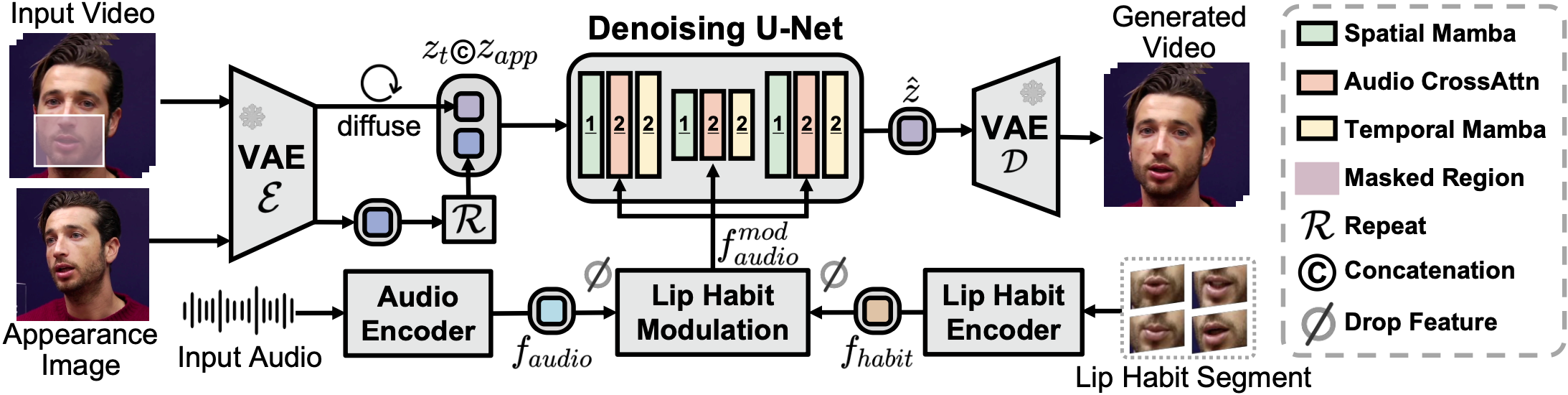
In this paper, we propose StableDub, a novel and concise framework integrating lip-habit-aware modeling with occlusion-robust synthesis.
Specifically, building upon the Stable-Diffusion backbone, we develop a lip-habit-modulated mechanism that jointly models phonemic audio-visual
synchronization and speaker-specific orofacial dynamics. To achieve plausible lip geometries and object appearances under occlusion, we
introduce the occlusion-aware training strategy by explicitly exposing the occlusion objects to the inpainting process.
By incorporating the proposed designs, the model eliminates the necessity for cost-intensive priors in previous methods, thereby exhibiting
superior training efficiency on the computationally intensive diffusion-based backbone. To further optimize training efficiency from the
perspective of model architecture, we introduce a hybrid Mamba-Transformer architecture, which demonstrates the enhanced applicability in
low-resource research scenarios. Extensive experimental results demonstrate that StableDub achieves superior performance in lip habit
resemblance and occlusion robustness. Our method also surpasses other methods in audio-lip sync, video quality, and resolution consistency.
We expand the applicability of visual dubbing methods from comprehensive aspects.
Demo videos may take up to 1 minute to load. Please wait...
Please expand video to full screen and unmute for better observation.